55. 요인 분석 적용과정
1) 요인분석의 절차
(1) 1단계: 조사 문제 정의
| 고려사항 | Ÿ 표본의 수는 변수 수의 3~4배 이상을 권장함. 따라서 변수 수가 늘수록 그만큼 더 많은 표본을 확보해야 하는 어려움이 따름 Ÿ 일반적으로 50개 이하이면 행하지 않는 것이 좋음. 최소한 100개 이상 되는 것이 바람직함 |
| 입력변수의 전제조건 |
Ÿ 등간척도나 비율척도로 측정된 양적변수(연속형 척도)가 활용됨. 이는 변수들 간의 상관관계 분석에 기초하여 이루어지기 때문임 Ÿ 독립변수는 독립적이고, 분산이 동일한 정규분포 형태가 되어야 함 Ÿ 변수들 간 상관관계가 있어야 함 |
(2) 2단계: 자료의 입력 및 표준화
■ 입력: 연속적 측정항으로 조사된 변수의 측정단위는 무시하고 그대로 입력함
■ 표준화: 측정단위를 고려하여 표준화시킨 자료로 바꿔, 측정단위의 차이로 인해 발생할 수
있는 영향을 제거함
(3) 3단계: 상관관계 계산(correlation matrix)
| ■ 변수들 간 상관관계행렬을 구상함으로써 변수들 간 상호관련성 파악함 ■ 변수들 간의 척도가 상이한 경우: 공분산행렬(covariance matrix) 이용 ■ 요인분석은 궁극적으로 상관관계가 높은 변수들을 묶게 됨 |
(4) 4단계: 요인 추출모델의 선정
■ 요인(factor): 서로 상관계수가 높은 변수들끼리 모아 작은 수의 변수 집단으로 나눈 것으로
변수 간 선형 결합을 의미함

■ 대표적 요인추출모델의 유형
| 주성분분석(primary component analysis) |
Ÿ 데이터의 전체 분산(총분산)을 토대로 요인을 추출하는 방법 Ÿ 정보의 손실을 최대한으로 줄이면서 수많은 변수를 가능한 적은 수의 요인으로 줄이는 데 목적이 있음 |
| 공통요인분석(common factor analysis) |
Ÿ 요인분석 시, 공통영역*과 측정변수가 가지는 특유의 고유영역 중, 측정변수의 공통영역을 추출하는 수학적 방법 *공통영역: 측정 변수들에 공통으로 잠재해 있는 이론적인 변수 |
| 주축요인분석(primary axis factoring) |
Ÿ 공통성(communality)의 초기 추정값으로서 대각선으로 배치된 제곱 다중 상관계수를 사용하여 원래의 상관행렬로부터 요인 추출 방법 Ÿ 대각선으로 위치하는 기존의 공통성 추정값을 대신하는 새로운 공통성을 추정하는 데 사용 Ÿ 공통성에 대한 변화량이 추출에 대한 수렴 기준을 만족할 때까지 반복은 계속됨 |
| 최대우도추정법 (maximum likelihood estimation) |
Ÿ 현상이 발생할 수 있는 우도*를 진단하고 이를 최대화할 수 있는 상태를 최적의 추정으로 가정하여 분석값을 찾는 방안 *우도: 어떤 사건이 이미 발생한 이후에, 발생한 사건이 가장 빈번하게 일어날 사건 혹은 평균적으로 일어날 사건과 일치할 확률 |
(5) 5단계: 아이겐 값을 기준으로 요인 도출
■ 고유값(아이겐 값, eigenvalue)
- 총분산 중에 해당 요인(factor)이 설명하는 비율
- 각각의 요인으로 설명할 수 있는 변수들의 분산 총합으로 각 요인별로 모든 변수의 요인
적재값을 제곱하여 더한 값
- 변수 속에 담겨진 정보(분산)가 어떤 요인에 의하여 어느 정도 표현될 수 있는가를 말해
주는 비율로 먼저 추출된 요인의 고유값이 다음에 추출되는 값보다 큼
| ① 요인이 설명해 줄 수 있는 분산의 정도를 의미함 ② 아이겐 값이 1이라는 것은 변수 하나 정도의 분산을 축약함 ③ 일반적으로 아이겐 값이 1이상인 요인들을 설정함 ④ 적어도 각 요인이 한 변수의 분산정도보다는 커야 한다고 보는 것 |
■ 분산기준
- 연구주제 따라 다르지만, 일반적으로 총 분산의 60% 정도 설명하는 요인추출
- 변수의 축약과정에서 정보의 손실이 일정수준 이상으로 커서는 안 되는 경우가 있을 수
있기 때문에 분산을 기준으로 함
| ① 공통분산: 하나의 변수가 다른 입력변수들과 관련되어 움직이는 공통적인 변량을 나타내는 분산임 ② 고유분산: 다른 입력변수들과 관계없이 해당되는 변수만이 독자적으로 가지고 있는 독특한 변량을 나타내는 분산임 ③ 오차분산: 공통분산이나 고유분산이 아니라, 측정과정에서 무작위로 발생할 수 있는 측정오차에 따른 변동을 나타내는 분산임 |
(6) 6단계: 요인적재량(factor loading) 산출
■ 요인적재량: 변수들과 요인 간의 상관계수로 요인적재값의 제곱은 해당 변수가 요인에 의하
여 설명되는 분산의 비율을 나타냄
| 요인적재량 산출 기준 |
■ 요인적재량이 0.4 이상 되면 유의한 변수로 간주 / 0.5가 넘으면 아주 중요한 변수로 봄 ■ 상관관계 검정을 통해 변수의 유의성을 체크함 ■ 표본수, 변수의 수, 요인의 수가 변함에 따라 고려함 - 표본의 수가 증가할수록 요인적재량의 고려수준 낮춤 - 변수의 수가 증가할수록 요인적재량의 고려수준 낮춤 - 요인의 수가 많을수록 나중 요인에 대한요인적재량의 고려수준 높임 |
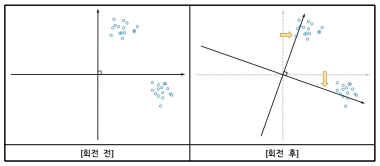
(7) 7단계: 요인의 회전*
■ 요인의 회전: 요인행렬을 좌표계 위에서 새롭게 생각한다는 의미로 행렬의 각 성분들은 좌표
축에 최대한 근접할수록 내용적 해석이 간편함
■ 직각회전(orthogonal rotation): 요인들 간의 상관관계가 없다고 가정(상관계수 = 0)하고 요
인을 회전시키는 방법으로 각 요인 간의 각도를 90도로 유지하면서 회전시킴. 즉 요인 간
독립성을 유지한 상태에서 개선하는 방법
| 배리맥스회전(VARIMAX) | ■ 요인행렬의 열을 단순화시키는 방법으로 보편적으로 이 방법을 사용함 ■ 요인행렬의 각 열에 1 또는 0에 가까운 요인적재량을 보임 ■ 변수와 요인 간 관계가 명확해지고 해석하기가 용이하여 단순한 요인구조를 산출 시 사용함 |
| 쿼티맥스회전 (QUARTIMAX) |
■ 요인행렬의 행을 단순화시키는 방식 ■ 한 변수가 어떤 요인에 대해 높은 요인적재량을 가지면 다른 요인에 대해서는 낮은 요인적재량을 가지게 함 ■ 많은 변수에 대해 문항 간 높은 적재량을 갖는 변수들의 일반적 요인을 만들어내는 데 적합함 |
| 이쿼맥스회전(EQUMAX) | ■ 배리맥스와 쿼티맥스를 절충한 방법 |
[직각회전 개념]
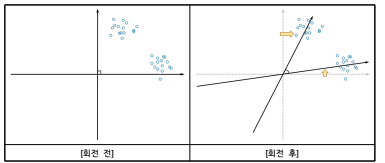
■ 비직각회전(oblique rotation): 요인 간 상관관계가 있다고 가정되는 경우에 사용하는 것으로
요인 간 각도를 90도 외의 사각(사선)을 유지하면서 변수를 회전시키는 방법
[비직각회전 개념]
(8) 8단계: 요인분석 결과의 평가 – 요인적재량행렬
■ 요인적재량 행렬의 각 행에서 적어도 하나의 0이 있어야 함
■ 요인적재량 행렬에서 각 열에는 최소한 common factor 수만큼의 0이 있어야 함
■ 두 개씩의 열을 비교할 때 많은 변수의 적재량이 가능한 한 열에 집중되어져야 한함
■ 요인의 수가 4개나 5개를 넘는 경우에는 양쪽이 모두 0이 되는 경우도 많아야 함
■ 0이 아닌 변수가 가능한 한 적어야 함
(9) 9단계: 요인의 해석
■ 요인이 추출되면 요인에 각기 명칭을 부여해야 함
■ 공통된 특성을 조사하여 연구자가 주관적으로 붙이거나 요인점수를 이용하여 추가적인 연결
분석을 통하여 규명할 수 있음
■ 연구자마다 상이하며 과연 요인이 의미 있게 추출되었는지에 대한 해석도 매우 주관적인 판
단에 의존함
■ 해석에 있어서 연구자의 주관이 많이 개입된다 하더라도 일반적인 상식과 어느 정도 일치해
야 한다는 점을 유의해야 함
(10) 10단계: 요인의 산출 및 분석 - 요인점수를 구하는 방법
■ 하나의 요인에 속하는 변수값들의 Z값을 구한 후 이를 합하여 요인점수로 정하는 방법
■ 하나의 요인에 속하는 변수값들의 Z값을 구한 후 이의 평균을 요인점수로 정하는 방법
■ 요인점수 계수를 이용하는 방법
2) 요인 분석 사례
(1) 분석 환경 설정
| ■ L社의 치약제품 마케팅 관리자는 소비자가 치약사용으로 인한 편익을 파악하여, 치약 구매에 얼마나 중요한지를 파악하고자 함 ■ 다음은 치약의 중요성 평가에 사용된 편익이며, 7점 척도를 통해 각 제품 편익이 치약 구매에 있어 중요하다는 것에 동의 시, 7점, 동의하지 않으면 1점을 부여하는 형태로 자료를 수집하였음 X1: 충치예방력, X2: 치약의 미백효과, X3: 잇몸강화정도, X4: 악취제거력, X5: 풍치예방력, X6: 매력적인 치아, X7: 튼튼한 치아 |
(2) 상관관계 계산과 주성분분석의 실시
■ 요인분석의 기본은 상관관계가 높은 변수를 함께 묶어 주는 것
■ 이를 위해 상관계수를 계산하고 주성분분석을 적용하여 초기 분석 결과를 도출하게 됨
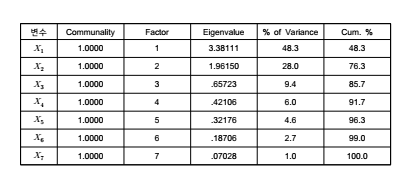
(3) 요인의 수 결정
■ 요인의 수는 최대 변수들의 수만큼 추출이 가능함
■ 본 사례의 경우 변수의 수가 7개이므로 최대 7개의 요인이 추출 가능함
■ 하지만 요인분석의 목적이 수를 줄이는 데 있어, 가능한 적은 수의 요인을 추출하는 것이 바
람직함
■ 이를 위해 아이겐값을 활용하게 됨(보편적으로 1이상인 요인을 선택하게 됨)
(4) 공통요인분석의 실시
■ 주성분분석을 통해 도출된 2개의 요인을 대상으로 요인행렬을 산출하게 됨
■ 요인행렬표에서 제시된 수치는 각 요인과 변수 간의 상관관계로 요인적재량이라 함
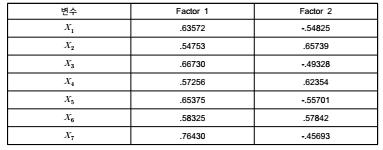
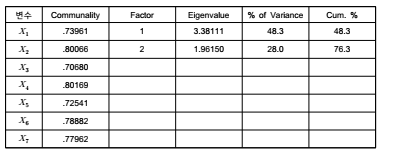
■ Communality 산출은 다음과 같이 Factor의 산출값의 제곱합을 통해 수행
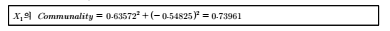
(5) 요인행렬표와 요인회전
■ 공통요인분석 시, 나타날 수 있는 문제점은 각 변수가 여러 요인과 동시에 높은 상관 관계를
보이는 것으로 X1의 경우 요인1(0.63572), 요인2(-0.54825)와 높은 상관관계를 가지고 있
음
■ 이는 각 요인 간 명확한 구분이 이루어지지 않음을 의미하는 것이며, 이를 조정하기 위해 회
전(rotation) 과정을 거치게 됨
- 요인1은 X1, X3, X5, X7과 높은 상관관계를 가지고, 요인2는 X2, X4, X6과 높은 상관관
계를 가지는 것으로 나타남
- 요인1과 요인2는 상호독립적임
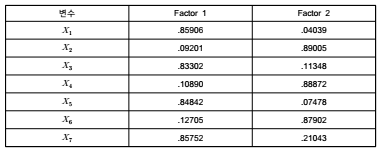
(6) 요인명의 결정
■ 요인1을 구성하는 항목에 대한 검토 결과 ‘치아의 건강’, 요인2는 ‘치아의 미’ 등과 같이 네 이밍을 하게 됨
(7) 요인점수 산출
■ 원래의 자료(X1~X7)에 대한 요인분석이 완료되면 각 응답자들이 대답한 값을 새로운 변수로
의 산출이 필요한데, 이를 요인점수라 함
Ÿ 요인점수는 요인점수계수(factor score coefficient)*를 이용하여 계산됨
- 요인점수계수: 응답자별로 각 요인점수를 구하는 데 이용된 원래 변수의 중요도(가중치)
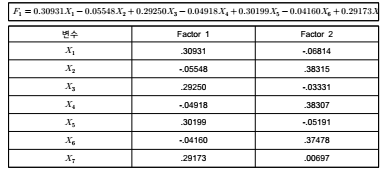
3) SPSS 수행 절차
(1) 1단계: [통계분석] → [데이터 축소] → [요인분석]
(2) 2단계: [요인분석] 창에서 요인 분석할 변수를 모두 [변수] 박스에 옮김
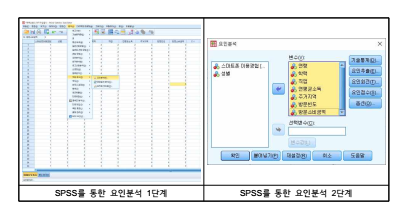
(3) 3단계: [기술 통계]를 누르면 새로운 창에서 ‘초기 통계’로 지정되어 있음
■ 초기 통계는 초기 communality, eigenvalue(고유치), 결정계수를 제공함
각 변수의 특성을 보다 자세히 파악하고 싶으면 ‘일변량 통계 기술’에 표시함
(4) 4단계: [요인추출]을 누르면 [요인분석: 요인추출] 창이 나타남
■ 요인추출방법으로는 ‘주성분 분석’이 가장 일반적으로 사용됨
(5) 5단계: [추출]에서 추출하고자 하는 요인 수를 지정함
■ 가장 일반적인 방법은 고유값(eigenvalue)이 1이 넘는 요인만 추출하는 것임
■ 다른 방법 : 미리 추출하고자 하는 요인의 수를 지정할 수도 있음
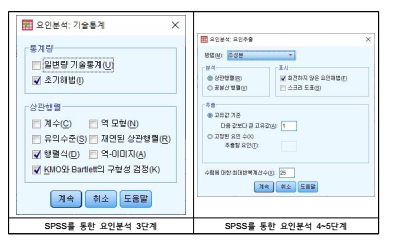
(6) 6단계: [요인회전] 창에 들어가 배리맥스(Varimax)에 표시함
(7) 7단계: 추출된 요인점수를 저장하여 다른 분석에 추가적으로 사용하고 싶으면
[요인점수]를 누르고, ‘변수로 저장’에 표시함
(8) 8단계: [옵션]을 누르고 ‘크기순 정렬’에 표시함
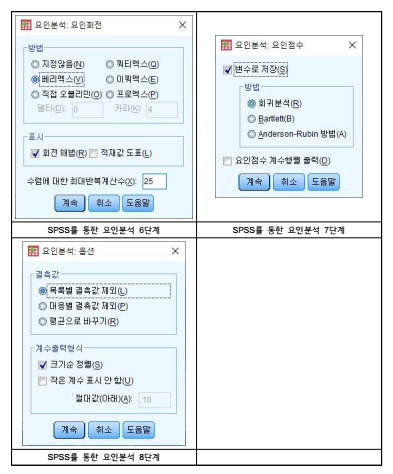
(9) 9단계: [확인]을 누르면 [SPSS 출력 결과] 창에서 공통성, 설명된 총분산, 성분
행렬, 성분변환행렬 등의 표가 산출됨
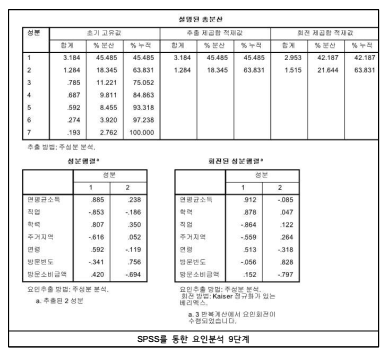
4) SPSS의 요인분석결과 및 해석방법
(1) 1단계: 공통성은 각 변수의 초기 값과 추출된 주요인에 의해 설명된 비율을 나타
냄(공통성은 0.4이하 일 때 낮게 평가됨)
(2) 2단계: 설명된 총분산에서 추출된 성분별 고유값이 나옴(일반적으로 사회과학에서
요구되는 설명된 총 분산은 60%이상임)
(3) 3단계: 성분행렬은 추출된 성분과 각 변수간의 관계를 나타냄
■ 회전된 성분 분열 표를 통해 각각의 변수가 어느 요인과 관련이 있는가를 판단할 수 있음
■ 두 요인 이상에 모두에 모두 높은 상관관계를 갖거나 어느 한 요인에도 높은 관계를 보이지
못하는 변수들이 있으면, 제거하고 다시 요인분석을 실시하는 것이 바람직함
(4) 4단계: 요인분석 결과를 토대로 다양한 기업 관련 변수들을 개별적으로 제시하지
않고, 요인별로 묶어서 제시할 수 있고, 요인점수를 이용하여 하나의 수치로 제시도 가능함
5) 요인분석 이용상의 고려사항
(1) 자료의 적합성 검정
■ 요인분석의 경우변수들의 상관관계를 기초로 상관관계가 높은 변수들끼리 묶는 것임
■ 의미 있는 요인분석이 위해서는 변수들 간의 상관관계가 일정수준 이상 되어야 함
■ 분석 시행 전에 상관관계행렬을 검토하여 자료의 적합성 여부에 대한 평가를 내려야 함
(2) 요인 수의 결정
■ 아이겐값을 기준으로 결정하거나 요인이 설명하는 분산의 정도에 따라 결정
■ 요인의 수, 많은 경우: 의미 있게 나올 수 있는 하나의 요인이 의미 없는 여러 요인으로 분
리되어 버릴 위험
■ 요인의 수, 너무 적은 경우: 요인구조에 문제가 생길 수 있음
(3) 상관관계의 문제
■ 요인분석은 기본적으로 변수들 간의 상관계수로부터 시작됨
■ 상관계수의 문제인 정규성, 범위, 분포 등의 문제를 원천적으로 포함함.
■ 정규성의 문제: 표본의 수가 증가함에 따라 해결될 수 있음
■ 설문지의 작성 단계와 자료수집 단계에서부터 많은 주의를 기울여야 함
(4) 회전의 문제
■ 일반적으로, 직각회전(orthogonal rotation) 중 VARIMAX가 많이 이용됨
■ 요인 간에 완전히 독립적이라고 보기 힘든 경우: 비직각회전 분석해야 함
(5) 원자료의 정보유지
■ 원자료의 정보손실을 최소(원자료의 정보는 가능한 한 유지)
■ Communality가 높아야 함(낮은 경우: 요인분석의 의미가 희박)
(6) 요인분석의 효율성
■ 4~5개 정도의 변수를 두 개의 요인으로 묶는 정도의 분석은 의미 없음
'시장조사론' 카테고리의 다른 글
| 경영학, 경제학, 경영지도사 대비 시장조사론 핵심 요점 정리 57. 군집 분석 적용과정 (1) | 2024.07.10 |
|---|---|
| 경영학, 경제학, 경영지도사 대비 시장조사론 핵심 요점 정리 56. 군집 분석 개념 (0) | 2024.07.09 |
| 경영학, 경제학, 경영지도사 대비 시장조사론 핵심 요점 정리 54. 요인 분석 개념 (0) | 2024.07.07 |
| 경영학, 경제학, 경영지도사 대비 시장조사론 핵심 요점 정리 53. 판별 분석 적용과정 (2) | 2024.07.06 |
| 경영학, 경제학, 경영지도사 대비 시장조사론 핵심 요점 정리 52. 판별 분석 개념 (2) | 2024.07.05 |



