53. 판별 분석 적용과정
1) 판별식의 도출
(1) 판별 분석은 독립변수를 적절히 조합한 새로운 판별식을 만들어 대상에 대한 집
단 구분이 보다 명확히 이루어질 수 있도록 하는 통계 기법임

(2) 판별식의 설계와 도출
■ 판별식(discriminant function): 독립변수들 간의 선형 결합을 통해 종속변수(Y)가 독립변수
들(X1, X2, X3...)의 1차식에 의해 설명될 수 있는 함수를 의미함
■ 집단 간의 차리를 가장 잘 판별할 수 있는 판별식, 즉 새로운 축 Y를 찾아내는 기법이며, 판
별식에서의 각 독립변수의 계수를 추정하는 것과 같은 의미임
■ 판별분석에서는 Y축을 조금씩 변화시키면서 집단 내 변이는 가능한 작게, 집단 간 변이는
가능한 크게 하는 조건을 만족시키도록 계수의 최적 추정치를 구하게 됨. 즉 집단 간 차이가
크기 위해서는 집단 간의 중복이 적어야 함
2) 추정되는 판별식의 수
(1) 하나의 판별식으로 조사대상의 소속을 구분할 수 있으면 이상적이나, 집단의 수
(또는 독립변수의 수)가 많아지면 명확한 집단 구분을 위해 많은 수의 판별식이
이용되기도 함
(2) 판별 분석에서 추정되는 판별식의 수는 ‘독립변수의 수’와 ‘집단의 수 – 1’ 중 작
은 값 이하이어야 함
■ 예) 독립변수 5개, 집단 수 2개일 경우, 판별 분석을 통해 추정되는 판별식은 1개임
■ 만약 2개 이상의 판별식이 얻어질 경우, 첫 번째 판별식이 집단을 가장 잘 판별하며, 두 번
째 판별식은 첫 번째 판별식을 보조하여 집단구분에 필요한 추가적 정보를 제공함
3) 판별 분석의 절차
(1) Step #1. 변수 선정
■ 종속변수
- 전체대상자들을 몇 개의 집단으로 나누어 분석할 것인가를 결정
- 사전에 집단들에 대한 연구를 하거나 다른 연구의 결과를 참조
- 각 집단들이 상호 배타적이고, 어느 대상이든 한 집단에 소속되어야 함
■ 독립변수
- 사전연구나 문헌을 통하여 의미 있는 것으로 밝혀진 변수를 이용
- 연구자의 경험과 직관이 많이 작용함
(2) Step #2. 표본 선정
■ 일반적으로 전체표본을 분석표본과 유보표본으로 나눈 뒤 분석표본을 사용하여, 판별식을 유
도하며, 유보표본을 사용하여 판별식의 타당성을 검토함
■ 분석표본과 유보표본을 분리하지 않고 같은 표본으로 사용할 경우, 판별식이 실제로 나타나야 되는 값보다 훨씬 의미 있는 것으로 나타남
(3) Step #3. 결과 해석
■ 판별분석 결과에서 입력/제거된 변수는 집단을 구분하는데 유의하게 영향을 미치는 변수만
을 선택하고, 나머지 변수들은 제외함을 나타냄
■ 케이스별 통계량 산출표에서는 개개 사례별로 실제 응답과 판별함수에 따른 예측 응답이 제
시됨
■ 판별분석이 제대로 되지 않은 것은 후보자 선택에 영향을 미치는 다른 중요한 요인이 고려
되지 못했기 때문임
4) 판별식의 유의성 검증
(1) 둘 이상의 판별식이 추정될 수 있을 시, 이들 식이 모두 의미 있는 것은 아님
(2) 따라서 각 식에 대해 유의성을 검증하고 의미없는 식은 분석에서 제거해야 함
(3) 추정된 판별식의 집단 간 차이를 판별하는 데 사용되는 검증은 Wilks’ Lamda(λ)
값에 의해 이루어짐

■ 집단 간 분산이 집단 내 분산에 비해 상대적으로 커질수록(즉, 집단 간의 차이가 클수록) λ
값이 작아지게 됨. 따라서 λ값이 작을수록(0에 가까울수록) 판별식(함수)의 집단 간 판별력
이 높다고 할 수 있음
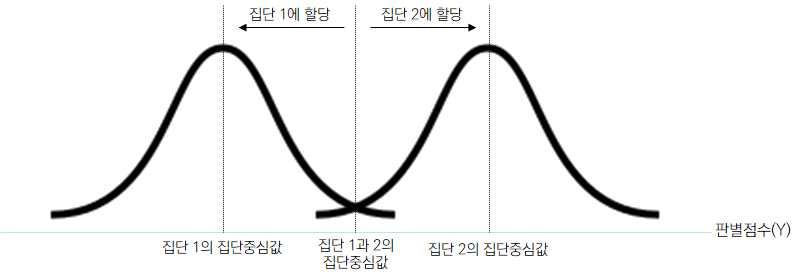
5) 집단중심값과 조사대상에 대한 집단 판별
(1) 집단중심값: 각 집단구성원들의 판별점수의 평균을 의미하며 조사대상자들의 소
속 집단을 분류하는 데 이용됨
(2) 개별 표본에 대해 산출된 판별점수와 집단중심값을 비교하여 그 대상의 소속집단
이 결정됨
6) 판별식의 판별력(설명력)
(1) 도출된 판별식이 각 응답자의 소속 집단을 얼마나 정확히 예측하는가를 검토해야 함
(2) 이를 위해 판별식의 판별력을 분류표를 통한 ‘hit ratio’를 산출하여 파악함
■ 판별력: 판별식이 각 표본의 소속집단을 얼마나 잘 분류하는지에 대한 값
■ 분류표: 각 표본의 실제소속집단과 판별식에 의해 예측된 소속집단 간의 교차표
■ hit ratio: 정확히 분류된 표본의 수를 전체 표본의 수로 나눈 값
(3) 예시
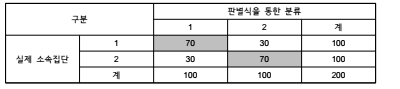
■ hit ratio: 140 ÷ 200 = 0.7
7) 판별 분석의 실제 적용 사례
(1) 사례 설정
| ■ H社는 4륜구동형 승용차를 사는 소비자와 일반 승용차를 사는 소비자를 판별식을 통해 구분하고자 함 ■ 이를 통해 소비자 유형별로 판촉 프로그램을 차별화하여 운용하고자 함 |
(2) 변수의 선정
■ 집단 간의 차이를 설명해줄 수 있는 변수를 독립변수로 선정해야 함
- 소득(X1), 연령(X2), 주거지역(X3), 여가생활(X4), 그리고 교통사고에 대한 걱정 정도(X5)
등을 독립변수로 설정함
- 집단 별로 각 100명씩에 대한 소비자 자료를 수집함
(3) 판별식의 수
■ ‘변수의 수’ 5와 ‘집단의 수(2) - 1’ 중 적은 수인, 하나의 판별식이 기대됨
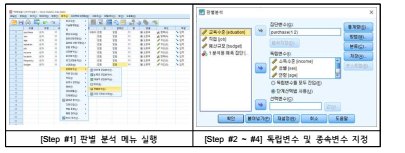
(4) 판별 분석의 SPSS 수행절차
■ (Step #1) [통계분석] - [분류분석] - [판별분석]으로 들어감
■ (Step #2) [판별분석] 창에 들어가 집단변수에 종속변수를 넣고 변수값의 범위를 지정함
- 종속변수: 차량용 구매자(명목척도 측정)
■ (Step #3) 다음에 종속변수에 영향을 미친다고 생각되는 독립변수를 지정함
- 독립변수: 소득(X1), 연령(X2), 주거지역(X3), 여가생활(X4), 그리고 교통사고에 대한 걱정
정도(X5) 등 5개(등간 또는 비율척도로 측정)
■ (Step #4) 판별분석의 방법에는 독립변수 모두를 강제 선택하는 방법과 변수를 하나씩 단계
적으로 투입하는 단계 선택적 방법이 있음(일반적으로 단계적 선택적 방법을 사용함)
■ (Step #5) [방법]을 클릭하고 Wilks의 람다를 선택함
■ (Step #6) [분류]를 클릭하고 각 케이스에 대한 결과와 요약 표에 표시함
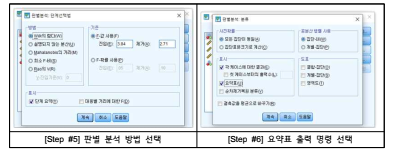
■ (Step #7) [판별분석] 창으로 돌아와 [확인]을 누름
(5) SPSS 결과에 대한 해석
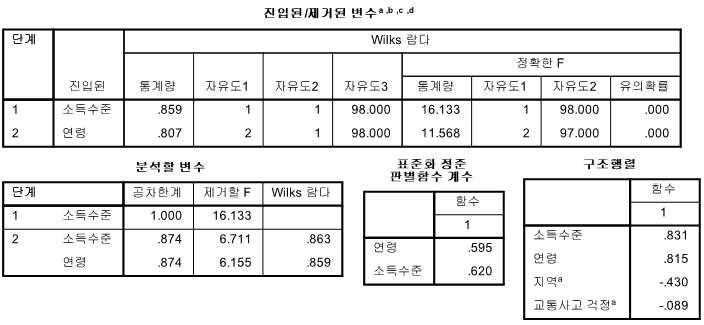
■ 판별식(함수)
- 입력한 5개의 변수 중 연령과 소득을 제외한 3개는 제거됨. 최종적으로 연령과 소득의 2
가지 독립변수를 통해 4륜구동형 자동차 구매 그룹에 대한 분할이 가능해 짐
- Y = 0.595X2(연령) + 0.620X1(소득)
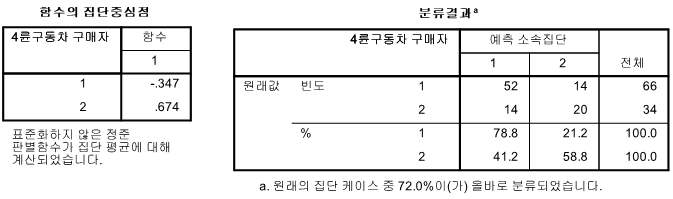
■ 집단중심값
- 4륜 구동차 구매자: -.347
- 4륜 구동차 구매자 외: .674
■ hit ratio: 72.0%
'시장조사론' 카테고리의 다른 글
| 경영학, 경제학, 경영지도사 대비 시장조사론 핵심 요점 정리 55. 요인 분석 적용과정 (1) | 2024.07.08 |
|---|---|
| 경영학, 경제학, 경영지도사 대비 시장조사론 핵심 요점 정리 54. 요인 분석 개념 (0) | 2024.07.07 |
| 경영학, 경제학, 경영지도사 대비 시장조사론 핵심 요점 정리 52. 판별 분석 개념 (2) | 2024.07.05 |
| 경영학, 경제학, 경영지도사 대비 시장조사론 핵심 요점 정리 51. 다중회귀분석 (1) | 2024.07.04 |
| 경영학, 경제학, 경영지도사 대비 시장조사론 핵심 요점 정리 50. 단순회귀분석 (1) | 2024.07.03 |



